Die OCR-Technologie (Optical Character Recognition) hat die Digitalisierung von gedrucktem oder handgeschriebenem Text aus physischen Dokumenten und dessen Bearbeitbarkeit und Durchsuchbarkeit grundlegend verändert. Das Entfernen von OCR aus einer PDF-Datei bedeutet im Wesentlichen, den Text in der PDF-Datei wieder in Bilder umzuwandeln oder einfach die erkannte Textebene zu entfernen. Es gibt verschiedene Möglichkeiten, wie Sie OCR aus PDF-Dateien entfernen können.
In diesem Artikel führen wir Sie Schritt für Schritt durch den Prozess des Entfernens von OCR aus PDF-Dateien. Lesen Sie weiter und finden Sie heraus, wie Sie OCR aus PDF entfernen können.
Bevor Sie lernen, wie Sie OCR aus PDF-Dateien entfernen, finden Sie hier ein kurzes Verständnis von OCR und warum Sie es möglicherweise aus Ihrer PDF-Datei entfernen müssen.
1. Was ist OCR in PDF?
Optical Character Recognition (OCR) bezieht sich im Zusammenhang mit einer PDF-Datei auf den Prozess der Konvertierung von gescannten oder bildbasierten PDF-Dokumenten in machine-lesbaren und durchsuchbaren Text. Eine PDF-Datei kann Text enthalten, der entweder als auswählbarer Text eingebettet oder als Bilder dargestellt wird.
OCR-Technologie wird verwendet, um Text aus diesen bildbasierten PDFs zu extrahieren, wodurch es möglich ist, den Text innerhalb des Dokuments zu suchen, zu kopieren, zu bearbeiten und zu bearbeiten. OCR wird häufig verwendet, um gedruckte Materialien zu digitalisieren, das Dokumentenmanagement zu verbessern und Dokumente zu archivieren.
2. Warum OCR aus PDF entfernen?
Zu den Gründen, warum Sie OCR aus PDF-Dateien entfernen möchten, gehören:
3. Was sind die Vorteile der Verwendung eines OCR-Entferners?
Die Verwendung eines leistungsstarken OCR-Entferners hat eine Reihe von Vorteilen, darunter:
4. Wie entferne ich OCR-Ebenen aus PDF online?
Es gibt mehrere manuelle Methoden, mit denen Sie OCR-Ebenen aus PDFs entfernen können. Eine der gebräuchlichsten ist das Drucken der PDF-Datei. Die Standarddruckfunktion von Windows entfernt angeblich die Textebene. Eine andere Möglichkeit, die OCR-Ebene aus PDF zu entfernen, ist ein Befehlszeilenprogramm – d. h. das Schreiben eines Skripts.
5. Woher weiß ich, ob eine PDF-Datei mit OCR versehen wurde?
Öffnen Sie die PDF-Datei und suchen Sie, ob Sie nach Wörtern in der Datei suchen oder ob Sie einen beliebigen Text auswählen können. Wenn Sie keinen Text auswählen oder in der PDF-Datei suchen können, handelt es sich möglicherweise um ein gescanntes Bild. Wenn Sie hingegen Text in der PDF-Datei suchen oder auswählen können, besteht eine hohe Wahrscheinlichkeit, dass OCR angewendet wurde.
Weiterlesen:
Befreien Sie Ihre Dateien: Die Magie von PDF Secured Entfernen [Aktualisiert]
[Gelöst] So entfernen Sie Berechtigungen aus PDF-Dateien einfach und effizient
WPS ist eine Office-Suite für MS Windows, Android, macOS, iOS, Linux und HarmonyOS. Es kann Ihnen helfen, Dateien unterwegs zu erstellen und anzuzeigen, vorausgesetzt, Sie haben es in Ihrem Gadget installiert. Sie können auch WPS-Sonderfunktionen verwenden, um OCR mühelos aus Ihren PDF-Dateien zu entfernen. Hier erfahren Sie, wie Sie OCR-Text mit WPS Office aus PDF entfernen.
Schritt 1. Stellen Sie sicher, dass Sie WPS auf Ihrem Gerät installiert haben, und öffnen Sie dann Ihre PDF-Datei mit WPS.
Schritt 2. Klicken Sie im oberen Menü auf die Registerkarte "Werkzeuge", sobald Sie die PDF-Datei geöffnet haben.
Schritt 3. Wählen Sie "OCR" aus dem Werkzeugbedienfeld und ein Fenster mit OCR-Einstellungen wird geöffnet.
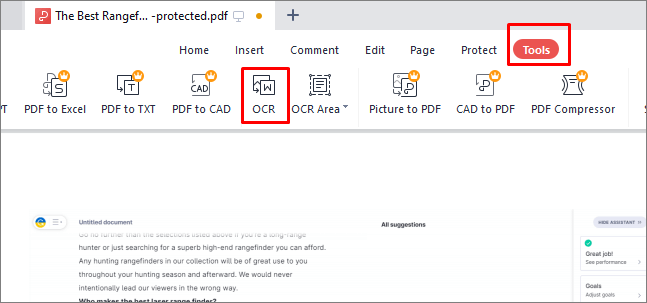
Schritt 4. Stellen Sie die OCR-Sprache auf "Keine" ein, um OCR aus der PDF-Datei im Dropdown-Menü OCR-Sprache zu entfernen.
Schritt 5. Klicken Sie auf "OK", um die Einstellungen zu speichern. Klicken Sie anschließend auf die Schaltfläche "Konvertieren", um die PDF-Datei ohne OCR zu konvertieren.
Schritt 6. Klicken Sie abschließend im oberen Menü auf die Schaltfläche "Datei", wählen Sie dann "Speichern unter" und benennen Sie die neue PDF-Datei entsprechend um.
Nicht verpassen:
Müheloses Entfernen des Hintergrunds aus PDF-Dokumenten [How-to-Tutorial]
[Nützliche PDF-Tipps] So öffnen Sie eine passwortgeschützte PDF-Datei ohne das Passwort
Adobe Acrobat bietet mehrere Funktionen für die PDF-Erstellung und -Bearbeitung. Eine dieser Funktionen ist das Entfernen von OCR aus PDF-Dateien. Sie können es als Desktop-Anwendung oder online über Ihren Webbrowser verwenden.
Mit Adobe Acrobat können Sie OCR für PDFs oder gescannte Dokumente deaktivieren bzw. entfernen. OCR ist in der Regel standardmäßig aktiviert. Wenn Sie also eine PDF-Datei oder ein gescanntes Dokument zur Bearbeitung öffnen, wird die aktuelle Seite in den meisten Fällen in bearbeitbaren Text umgewandelt. Glücklicherweise können Sie die automatische OCR-Option entfernen oder ein- und ausschalten, je nachdem, ob Sie Ihre Datei in bearbeitbaren Text konvertieren möchten oder nicht. Hier erfahren Sie, wie Sie die automatische OCR mit Adobe Acrobat aus PDF-Dateien entfernen.
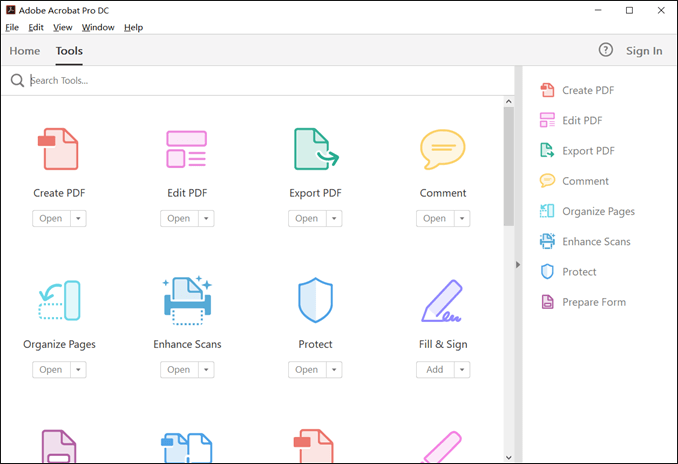
Schritt 1. Stellen Sie sicher, dass Sie Adobe Acrobat auf Ihrem Computer installiert haben. Starten Sie die App, navigieren Sie zu "Extras" und klicken Sie dann auf "PDF bearbeiten".
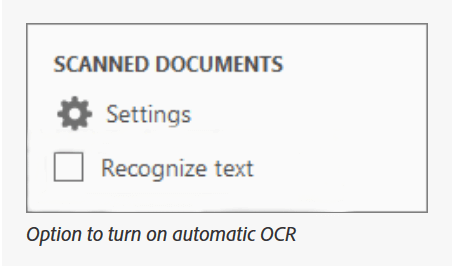
Schritt 2. Um OCR zu entfernen oder zu deaktivieren, gehen Sie zum rechten Bereich und deaktivieren Sie das Kontrollkästchen Text erkennen. Auf diese Weise aktiviert Adobe die OCR für Ihre PDF-Datei bzw. Ihr gescanntes Dokument nicht automatisch.
Anmerkung: Wenn die OCR-Ausgabe von "Durchsuchbares Bild" oder "Durchsuchbares Bild exakt" stammt, können Sie Adobe Acrobat Pro verwenden, um die OCR zu entfernen. Wenn Sie Adobe Acrobat X verwenden, gehen Sie zu "Extras"> "Schutz" > "Versteckte Informationen". Klicken Sie auf die Schaltfläche "Entfernen" im Bereich "Ausgeblendete Informationen entfernen". Wenn Sie neben dem Eintrag "Ausgeblendeter Text" ein Häkchen sehen, bedeutet dies, dass die OCR-Ausgabe entfernt wird.
Wenn Sie jedoch Adobe Acrobat 8 verwenden, gehen Sie zu "Dokument" und navigieren Sie dann zu "Dokument untersuchen". Klicken Sie auf das Symbol "Alle markierten Elemente entfernen" im Dialogfeld "Dokument untersuchen". Wenn der Eintrag Ausgeblendeter Text angehakt ist, bedeutet dies, dass die OCR-Ausgabe gelöscht wird.
Siehe auch:
[Einfache Anleitung] Konvertieren Sie Word in PDF über Adobe Acrobat & Alternativen
PDF to Word Magic: Konvertieren Sie PDF in Word mit Adobe Acrobat & Alternativen
Egal, ob Sie einen Stapel alter gedruckter Dokumente, einen handgeschriebenen Brief oder ein gescanntes Bild mit wichtigen Informationen haben, die Umwandlung in bearbeitbaren Text kann Ihnen Zeit und Mühe sparen. PDFelement ist eine vielseitige und benutzerfreundliche Softwarelösung, die Ihnen helfen kann, diese Aufgabe effizient zu erledigen. PDFelement kann OCR zwar nicht direkt aus PDF entfernen, aber gescannte Dokumente oder Text aus Bildern in bearbeitbaren Text umwandeln.
Neben der Konvertierung von gescannten Dokumenten und Text kann PDFelement mehrere andere PDF-Bearbeitungsfunktionen ausführen, wie z. B. das Entfernen von Kopf- und Fußzeilen aus PDFs, das Entfernen von Text aus PDFs, das Entfernen von ausfüllbaren Feldern aus PDFs oder das Entfernen von Wasserzeichen aus PDFs usw. Dieser Dokumentenkonverter wird aufgrund seiner Stapelverarbeitungsfunktion dringend empfohlen. Es kann mehrere PDFs gleichzeitig verarbeiten, ohne die Dateiqualität zu beeinträchtigen.
Zu den erstaunlichen Funktionen von PDFelement gehören:
Hier erfahren Sie, wie Sie PDFelement verwenden, um gescannte Dokumente oder Text aus Bildern in bearbeitbaren Text umzuwandeln.
01Laden Sie PDFelement herunter, installieren Sie es und führen Sie es auf Ihrem Gerät aus. Klicken Sie auf "PDF öffnen", um die PDF-Datei zur Bearbeitung hochzuladen.
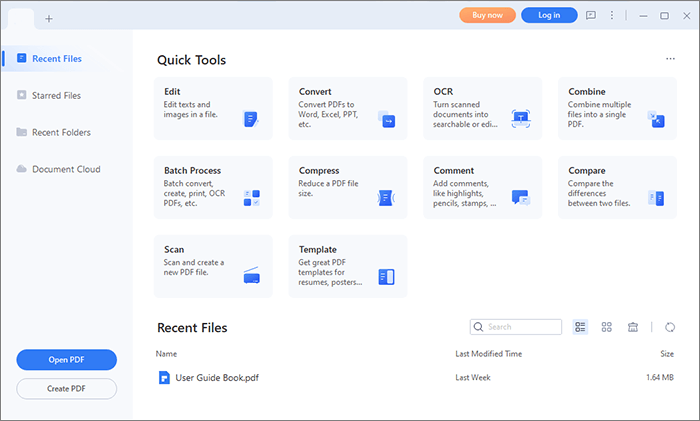
02Klicken Sie auf die Schaltfläche "Extras" und wählen Sie "OCR".
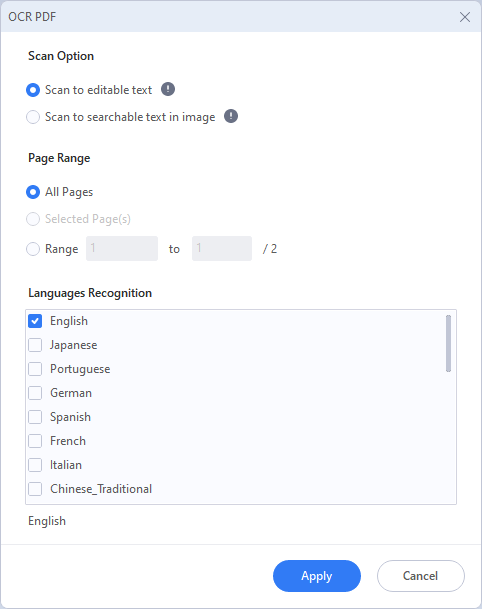
03An dieser Stelle erscheint ein Popup-Fenster. Wählen Sie "In bearbeitbaren Text scannen", wählen Sie dann die gewünschten Seitenzahlen und die gewünschte Sprache aus und klicken Sie auf "Übernehmen".
04Nachdem der Vorgang abgeschlossen ist, öffnet das Programm automatisch die neu erstellte bearbeitbare PDF-Datei. Sobald es geöffnet ist, können Sie auf die Schaltfläche "Bearbeiten" klicken, um Änderungen am PDF-Text vorzunehmen.
Kann mögen:
PDF-zu-Word-OCR-Software Review: Entfesselung von Präzision und Effizienz
Von Pixeln zu Absätzen: PDF-Bild-zu-Text-Konvertierung
Das Entfernen von OCR aus PDF-Dateien ist ein unkomplizierter Prozess und bietet mehrere Vorteile, darunter eine verbesserte Dokumentensicherheit, eine verbesserte Dateiqualität und eine erhöhte Kompatibilität zwischen verschiedenen Geräten und Plattformen. Um dies zu erreichen, benötigen Sie ein spezielles und praktisches Tool. Die Methoden und Lösungen, die wir hier besprochen haben, bieten Ihnen die Möglichkeit, OCR kostenlos aus PDF-Dateien zu entfernen, und für diejenigen, die erweiterte Funktionen suchen, stehen auch Premium-Alternativen zur Verfügung.
Wenn Sie jedoch die gescannten PDF-Dateien bearbeiten oder konvertieren möchten, gewinnt PDFelement . Es ist eine leistungsstarke PDF-Bearbeitungssoftware mit mehreren Fähigkeiten und Funktionen.
Verwandte Artikel:
Top PDF to Word Converter Free Offline: Konvertieren von PDF in Word leicht gemacht
[9 Tools Review] Der heißeste PDF-zu-Word-Konverter Online/Offline
[Machen Sie Ihr Büro einfach] Die 6 besten kostenlosen PDF-zu-Word-Konverter
Wie scanne ich ein Bild wie ein Profi in PDF? Ihr ultimativer Leitfaden
So fügen Sie eine PDF-Datei in ein Google-Dokument ein: Schnelle und einfache Schritte
[Effiziente PDF-Tipps] So erstellen Sie kostenlos einen URL-Link für ein PDF-Dokument

 Office-Lösungen
Erfahren Sie, wie Sie OCR wie ein Profi aus PDF-Dateien entfernen können - ein Expertenleitfaden
Office-Lösungen
Erfahren Sie, wie Sie OCR wie ein Profi aus PDF-Dateien entfernen können - ein Expertenleitfaden





 Kostenloser Download für PC
Kostenloser Download für PC  Kostenloser Download für Mac
Kostenloser Download für Mac 