PDFからデータを抽出し、他のアプリケーションで使用したいですか?PDF から読み込んで他のアプリケーションにデータを入力すると、時間がかかりすぎる場合があります。あなたのためにそれをするために誰かを雇うことは費用がかかるだけでなく、あなたの個人データを公開する可能性もあります。PDFからデータを抽出するためのより簡単で安全なソリューションがあります。Excelでデータを分析する場合でも、Wordで編集する場合でも、データを抽出する方法はたくさんあります。
PDFドキュメントは通常、テキスト、画像、および表を組み合わせたものです。PDFデータ抽出ツールを使用すると、抽出するものを選択できます。PDFからテキスト、画像、ページ、表を抽出するのに役立つさまざまなツールと手法を検討します。これらのツールを使用すると、多くの時間と労力を節約できます。
オフラインツールを使用すると、デスクトップ上のPDFからメタデータを抽出できます。オフラインPDFデータ抽出には、関連するソフトウェアが必要です。インターネットを必要とせず、機密データを公開しないため、これは優れたオプションです。このセクションでは、PDFからデータを抽出するための2つのオフラインツールについて説明します。
PDF要素を使用すると、PDFドキュメントを表示、作成、署名、変換、および編集できます。このアプリケーションは、Windows、Mac、Android、およびIOSを含むすべてのオペレーティングシステムで利用できます。オフラインバージョンには、最大1GBのクラウドストレージが含まれています。PDF要素を無料でダウンロードしてテストできます。PDF要素の最も優れている点は、オールインワンのPDFエディターであるということです。スキャンしたドキュメントの編集からファイルからのデータの抽出まで、PDFドキュメントでほぼすべてのことを行うのに役立ちます。
主な機能:
最高のPDFデータ抽出器無料ダウンロード。
PDF要素を使用してPDFからさまざまな種類のデータを抽出する方法は次のとおりです。
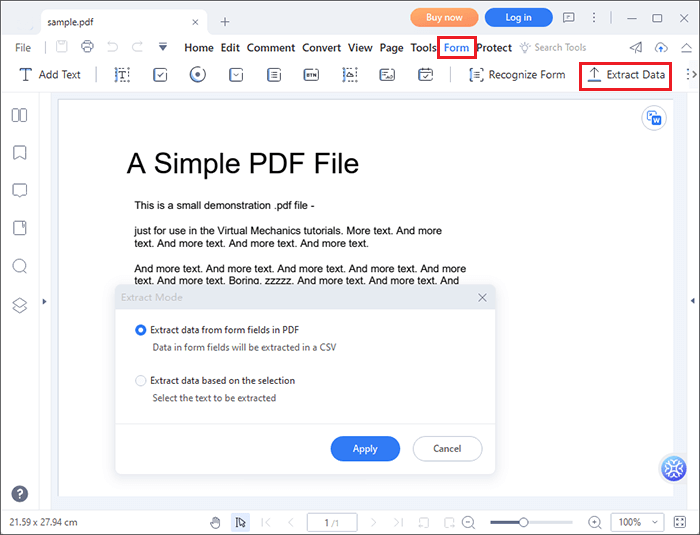
01月PDF要素を使用してPDFドキュメントを開きます。「フォーム」タブをクリックし、「フォームを認識」を選択します。PDF要素はフォーム内のフィールドを認識します。
02月[フォーム] タブから [データの抽出] をクリックします。ダイアログボックスが表示されます。
03月ダイアログボックスから最初のオプションを選択して、PDFのフォームフィールドからデータを抽出します。[ 適用 ] をクリックし、ファイルを保存する場所を選択します。PDF要素は抽出したデータをCSVファイルに保存し、Excelで開きます。
01月PDF ドキュメントを開きます。上部の [ 編集 ] タブをクリックします。
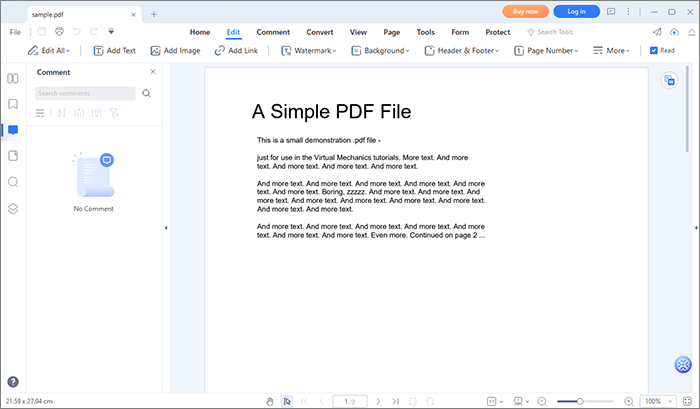
02月抽出するテキストをクリックします。テキストを囲む枠が表示されます。抽出するテキストの上にマウスをドラッグして強調表示します。強調表示したテキストを右クリックして[ コピー ]を選択するか、キーボードの Ctrl と C を押します。
03月空のワードプロセッサを開きます。それを右クリックして、[ 貼り付け]を選択します。または、キーボードの Ctrl キーと V キーを押します。テキストを取得したら、編集して保存できます。
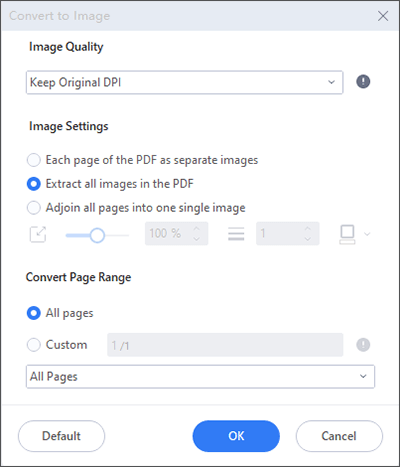
01月[ 変換 ]タブをクリックし、ツールから[ 画像へ ]を選択します。ダイアログボックスが開きます。
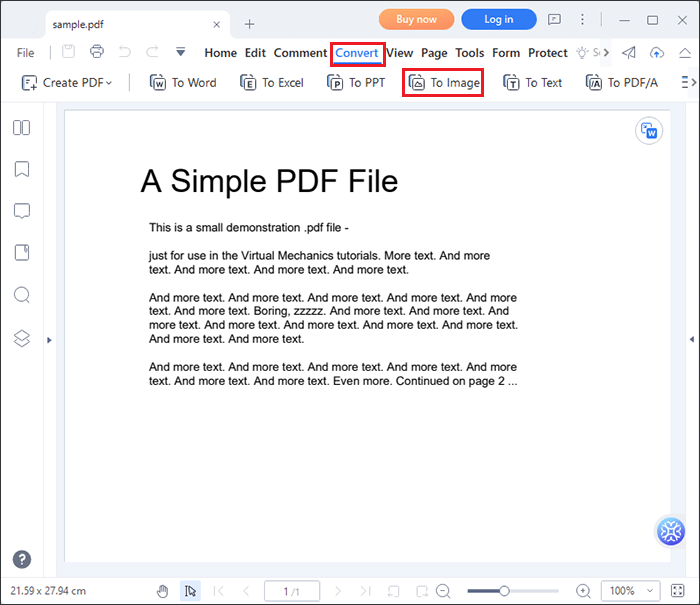
02月ダイアログボックスの [設定 ]アイコンをクリックします。別のダイアログボックスが開きます。
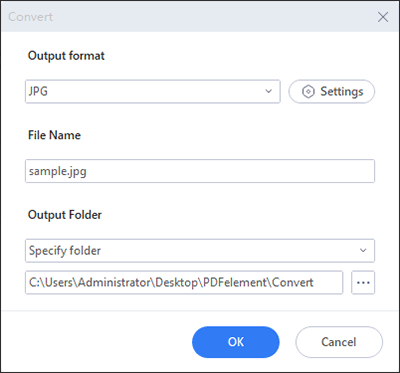
03月 PDF 内のすべての画像を抽出する オプションを選択し、「 OK」をクリックします。また、出力フォルダを指定した後、前のダイアログボックスで[ OK ]をクリックします。抽出プロセスが開始されます。出力フォルダを開いて、抽出された画像を表示します。
手記: 1つの画像のみを抽出する場合は、画像を右クリックして[ 名前を付けて画像を保存]を選択できます。ダイアログボックスがポップアップ表示されます。画像の名前を入力し、[ 保存] をクリックします。
01月PDF ドキュメントを開き、[ ページ ] タブを選択します。 [抽出 ] ツールをクリックします。小さなポップアップウィンドウが表示されます。
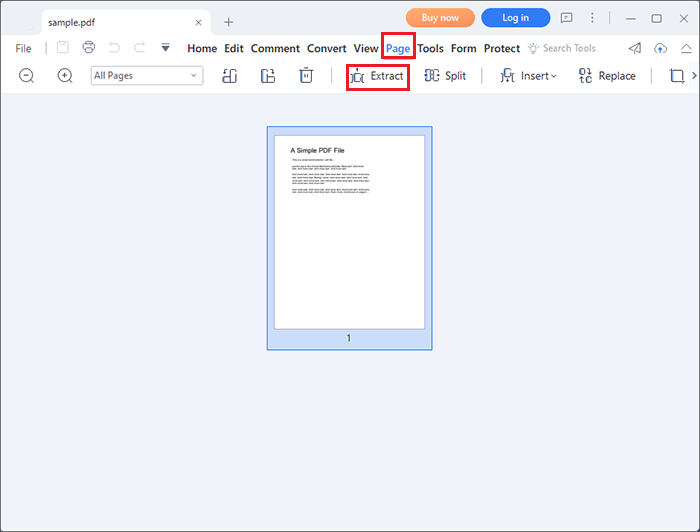
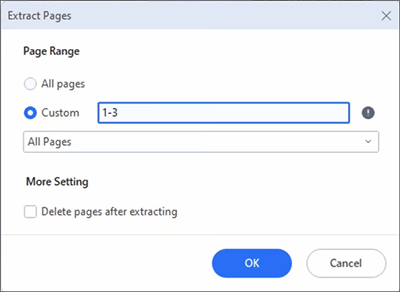
02月[ カスタム ] をクリックして、ファイルから数ページを抽出します。次に示すように、抽出するページ範囲を入力します。[ OK] をクリックし、抽出プロセスが完了するのを待ちます。PDF要素は、選択したページで新しいPDFファイルを作成します。新しいファイルを新しい名前で保存します。
参考文献:
PDFを高品質でPNGに変換する方法は?8 専門家のヒントとコツ
アドビアクロバットプロDCは、PDFドキュメントの表示と編集に役立つ高度なアプリケーションです。これを使用して、ページの暗号化、署名、 抽出、およびPDFファイルのさまざまな形式への変換を行うことができます。この場合、変換方法を使用してPDFデータを抽出する方法を示します。この方法では、PDF から Excel に特定のデータは抽出されません。すべてを抽出しますが、Excelで不要なものは削除できます。Adobe Acrobat を使用して PDF データを Excel に抽出する方法は次のとおりです。
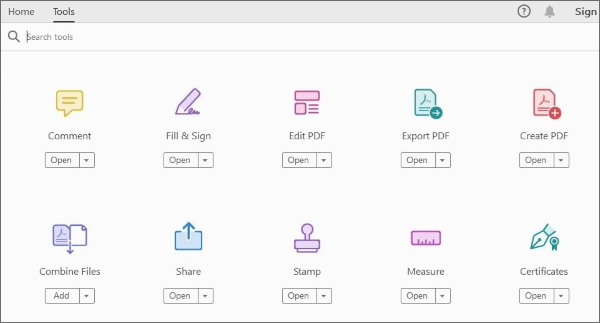
ステップ1.Adobe Acrobat を使用して PDF ドキュメントを開きます。[ ツール ] タブをクリックし、[ PDF のエクスポート] を選択します。
ステップ2.ファイルをエクスポートする形式として [ スプレッドシート ] を選択します。Office 2003 を使用している場合は、エクスポートする前にそのバージョンを選択します。それ以外の場合、それ以降のバージョンを使用する場合は、 Microsoft Excel ブック のままにします。
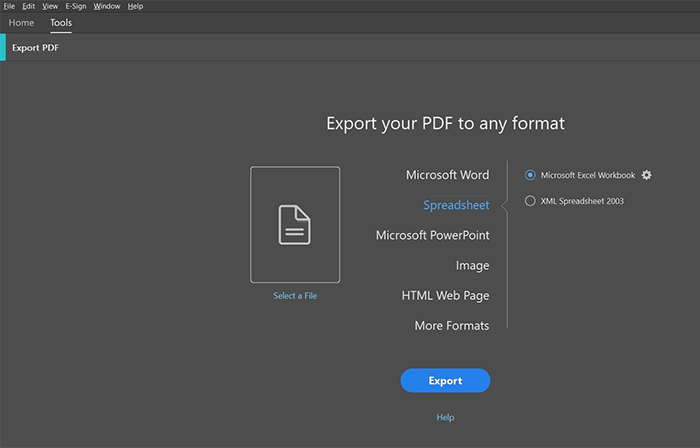
ステップ3.下部にある [ エクスポート ] をクリックします。[ 名前を付けて保存 ] ダイアログ ボックスでファイルを保存する場所を選択します。ファイル名を変更して [ 保存] をクリックすることもできます。Adobe Acrobat によってファイルが Excel にエクスポートされます。選択した保存場所に移動し、Excel ファイルを開きます。
Excel には Office 365 パッケージが付属しており、オンラインとオフラインで使用できます。このオプションは、Office 2007や2016などの他のOfficeバージョンでは使用できないことに注意してください。これらの以前のバージョンでは、Word および Access からデータをインポートできますが、PDF から Excel へのデータ抽出はサポートされていません。Office 365 をインストールするには、アクティブなサブスクリプションが必要です。ExcelがPDFからデータを抽出する方法は次のとおりです。
ステップ1.空の Excel ファイルを開きます。[データ] タブをクリックし、リボンの左側にある [データの取得] を選択します。ドロップダウンリストが表示されます。[ファイルから]、[PDF から] の順に選択します。
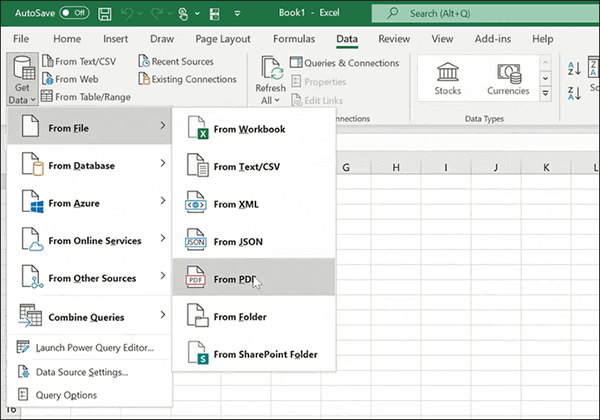
ステップ2. データのインポート ダイアログボックスで、 PDF ファイルを選択し、「 インポート」をクリックします。
ステップ3.PDF ファイルのページが表示されます。抽出するデータを含む PDF ページをクリックします。テーブルがプレビュー セクションに表示されます。テーブルに変更を加える場合は、[ データの変換] をクリックします。変更がない場合は、下部にある [ 読み込み ] をクリックして、テーブルを Excel シートに追加します。
ステップ4.データが Excel に格納されたら、ファイルを編集して保存します。
あなたは好きかもしれません:
TIFFをPDFに変換する方法:オンラインおよびオフラインの方法が明らかに
オンラインツールは、PDFデータ抽出ソフトウェアをインストールしたくない場合の優れた代替手段です。このオプションは、通常のコンピュータシステムから離れているときにも使用できます。PDFからデータを抽出するための3つのオンラインツールを見てみましょう。
Sejdaは、多くのPDFツールを備えたPDFメタデータ抽出ツールです。PDFからメタデータを抽出するのに役立つ無料トライアルがありますが、最大ファイルサイズには制限があります。このセクションでは、Sejdaを使用してPDFからデータを抽出する2つの方法を示します。
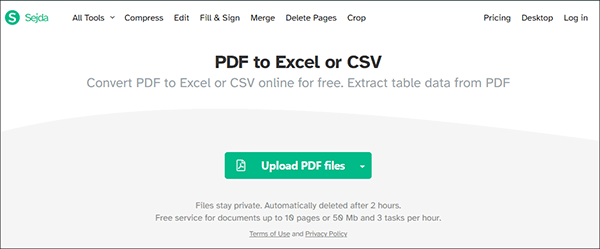
ステップ1.sejda.com にアクセスし、[すべてのツール]から[PDFからExcelへのコンバーター]を選択します。
ステップ2.[ PDFファイルをアップロード] をクリックするか、クラウドストレージからファイルを選択します。
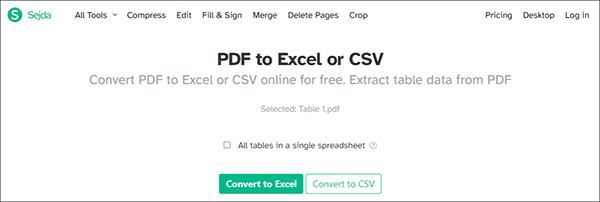
ステップ3.ファイルをアップロードしたら、すべての表を 1 つのスプレッドシートに表示するかどうかを選択します。[ Excel に変換] をクリックします。
ステップ4.[ ダウンロード ] をクリックして、変換されたファイルを保存します。Sejdaはファイルをエクセル形式でダウンロードします。ファイルを開くと、Sejdaを使用したPDFからExcelへのデータ抽出では、テーブルの歪みが発生しないことがわかります。
ステップ1.Sejda の Web サイトから [すべてのツール ] を選択します。左側の [その他 ]に移動し、[ 画像の抽出]を選択します。
ステップ2.[ PDF ファイルのアップロード] をクリックし、コンピューターからファイルを選択します。クラウドストレージからアップロードすることもできます。
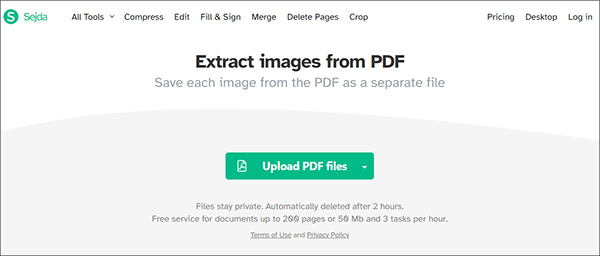
ステップ3.Sejdaを使用すると、ページ全体を変換したり、単一の画像を抽出したりできます。オプションを 1 つ選択し、[ 続行] をクリックします。
ステップ4.画像の解像度と形式を選択し、[ 変換]をクリックします。SejdaはPDFから画像を抽出し、選択した画像形式でダウンロードできるようにします。
PDF24は、PDFドキュメントから画像やページを抽出できる無料のオンラインツールです。以下は、PDF24を使用してPDFページを抽出するために従う手順です。
ステップ1.pdf24.org にアクセスし、ツールのパネルから [PDFページの抽出 ]を選択します。
ステップ2.[ ファイルを選択 ] をクリックし、アップロードする PDF ドキュメントを選択します。
ステップ3.PDF24 がファイルをアップロードし、そのページを表示します。抽出するページを選択し、[ ページの抽出] をクリックします。PDF24はページを抽出し、ダウンロードできるようにします。

詳細情報:
プロのように写真をPDFにスキャンする方法は?あなたの究極のガイド
ステップバイステップガイド:画像をPDFに結合する方法 オンラインおよびオフライン
PDF2Goは、PDFからデータを抽出するのに役立つ別のオンラインツールです。このツールは、画像やフォントの形式でPDFからデータを抽出する場合に最適です。以下は、PDF2Goからデータを抽出するために従うべき手順です。
ステップ1.pdf2go.com にアクセスして、ツールのパネルから アセットの抽出 を探します。
ステップ2.[ ファイルの選択 ] をクリックして、コンピューターから PDF ファイルをアップロードします。 ドロップダウン矢印 をクリックして、クラウドからファイルをインポートすることもできます。ファイルがアップロードされたら、[ 開始 ] をクリックして抽出を開始します。
ステップ3.PDF2GoはPDFファイルからフォントと画像を抽出し、それらを別々のファイルとして配置します。一度に1つの画像をダウンロードするか、zipファイル内のすべての画像をダウンロードするかを選択できます。
PDF情報を編集したり、別のアプリケーションで使用したりする場合に、PDFからのデータ抽出が必要になります。上記のツールとテクニックは、PDFから画像、テキスト、および表を抽出する最も簡単な方法を示しています。
PDFelement は、モバイルデバイスとコンピューターデバイスを使用して、どのオペレーティングシステムからでもアクセスできるため、タスクに最適なツールの1つとして際立っています。さらに、1つのアプリケーションから特定の種類のデータを抽出できます。今すぐPDF要素をダウンロードして、PDFからシームレスにデータを抽出してください。
関連記事:
PDFをWordに簡単に挿入する方法[包括的なチュートリアル]
テキストがなくなる:PDFからテキストを削除する方法[完全なチュートリアル]
PDFをWordに簡単にエクスポートするにはどうすればよいですか?究極のハウツーガイド
PDFレイアウトを保持する:PDFのページを簡単に分割する方法





 PC版ダウンロード
PC版ダウンロード  Mac版ダウンロード
Mac版ダウンロード 

