PDFは、コンテンツの操作が難しいため、オンラインでファイルを共有するために使用される一般的なドキュメント形式です。ただし、PDF ドキュメントからテーブルを抽出する必要がある場合がありますが、そのようなドキュメントに重要なビジネスデータが含まれている場合です。通常、手動で行うことにした場合、これは長くて面倒なプロセスです。
幸いなことに、多くのPDFテーブルエクストラクタを使用すると、PDFファイルからテーブルを簡単に削除できます。このタスクを初めて実行する場合は、最良の結果をもたらすツールについて混乱する可能性があります。この記事では、さまざまなオンラインおよびオフラインのPDF抽出ツールと、それらを使用してPDFテーブルをすばやく抽出する方法を共有します。

複数のPDFファイルからテーブルを抽出する便利な方法の1つは、オフラインPDF抽出ソフトウェアアプリケーションを使用することです。オンラインツールとは異なり、オフラインエクストラクタには、複数のPDFドキュメントから画像を抽出するオプションなど、多くの機能があります。一部のアプリケーションには、書式設定をそのまま維持しながら、PDFからテーブルを簡単に検出して削除できるOCR機能が含まれています。
オフラインツールは、高品質の出力を確保しながら、複数のPDFドキュメントからテーブルを抽出したい人にも理想的です。もう1つの重要な利点は、ほとんどのツールが異なるオペレーティングシステムと互換性があることです。
PDFエディタ を使用すると、ユーザーはドキュメントからテキストや表をすばやく抽出できます。これは、PDFファイルとスキャンされた画像を簡単に認識し、編集可能なファイルに変換するPDFエディターOCR(光学式文字認識)機能のおかげで可能です。変換ツールを使用して、PDFからExcelにテーブルを抽出することもできます。
このツールを使用してPDFからテーブルを抽出する利点は、MacやWindowsなどのさまざまなオペレーティングシステムと互換性があることです。また、PDFからファイルをすばやく簡単に削除できる使いやすいインターフェイスも備えています。
知っておくべきPDFエディタの主な機能は次のとおりです。
PDFエディタでPDFからテーブルの抽出を開始する準備はできましたか?従うべき手順は次のとおりです。
01月コンピューターに PDFエディター をダウンロードしてインストールして起動します。メインインターフェイスで、をクリックします PDFを開く お好みのファイルをアップロードします。メニューバーの フォーム ツールをタップし、[ テーブルの認識]をクリックします。これは、迅速なデータ処理のためにフォームフィールドを認識するのに役立ちます。
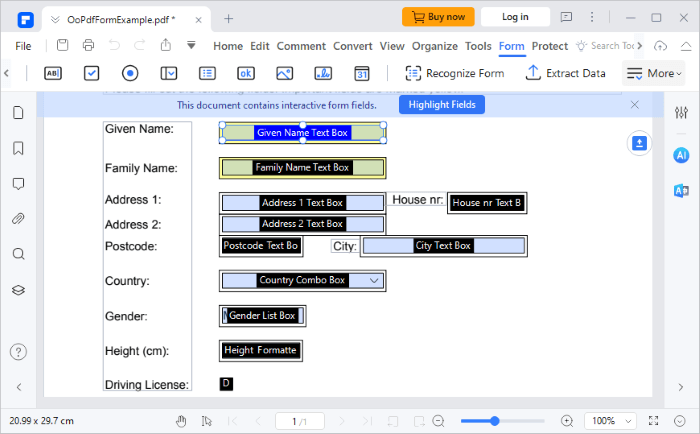
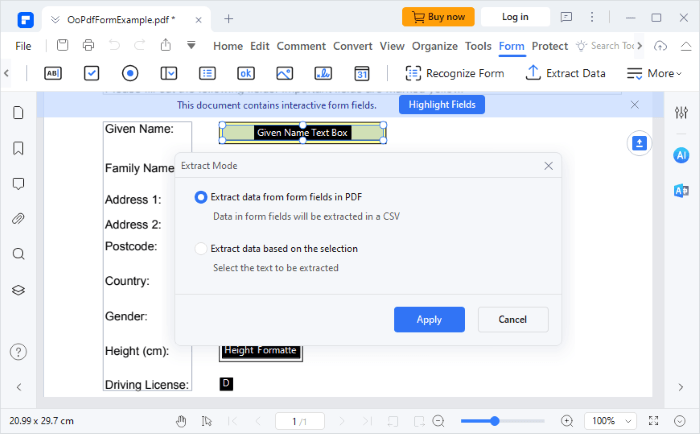
02月 フォーム ツールに戻り、[ データの抽出] オプションを選択します。ポップアップウィンドウが画面に表示されます。[ PDF のフォーム フィールドからデータを抽出 ] をクリックして、以前に選択したフィールドからテーブルを抽出します。
キャメロットは、PDFからテーブルをすばやく抽出できるPythonライブラリです。PythonのPDF抽出プログラムは、テキストベースのPDFドキュメントがあり、スキャンされた画像がない場合にのみ機能することに注意してください。
Pythonプログラムを使用してテーブルを抽出する際に従う必要のある手順は次のとおりです。
ステップ1. コンピューターにPython をインストールしたら、CMDコマンドウィンドウを開いて次のように入力してライブラリをインストールします。
ピップインストールキャメロットピー[CV]
ステップ2.新しい Python ファイルを作成し、コードを入力します。
キャメロットのインポート
テーブル = camelot.read_pdf('[あなたのPDFファイル]', フレーバー='ストリーム')
tables.export('extracted_tables.csv', f='csv')
ステップ3.Python ファイルを実行すると、PDF テーブルがファイル extracted_tables.csvに抽出されます。
続きを読む:
MacでPDFから画像を簡単に抽出する方法[7つの方法が含まれています]
Adobe Acrobatは、ユーザーがPDFファイルでさまざまな操作を実行できるようにする主要なPDF編集および読み取りツールの1つです。このツールを使用すると、 PDFドキュメントを暗号化、署名、さらには編集できます。このツールは、PDFからテーブルを抽出する場合にも役立ちます。一度も使用したことがない場合は、次の手順を実行する必要があります。
ステップ1.コンピューターに Adobe Acrobat DC をダウンロードしてインストールして実行します。メニュー バーの [ツール] オプションに移動し、[作成と編集] セクションで [PDF のエクスポート] の下の [開く] を選択します。
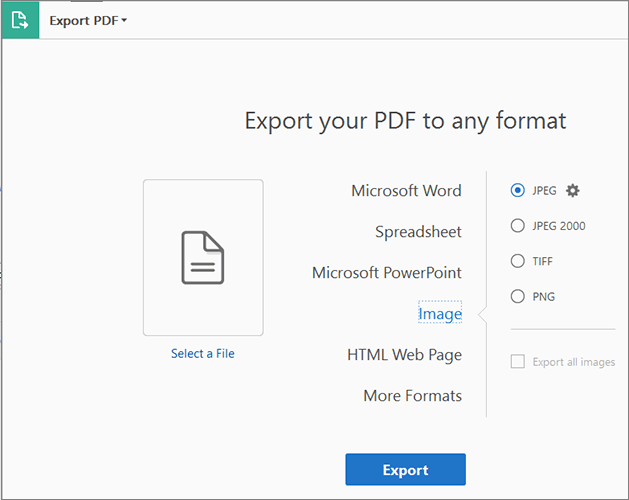
ステップ2.[ファイル の選択 ]オプションをタップして、PDFファイルを選択します。[ スプレッドシート] を選択し、[ MicrosoftExcelブック ]オプションを切り替えます。[ エクスポート] をクリックします。
ステップ3.クリック 宛先フォルダを選択 ドキュメントを保存する場所を選択します。新しいファイルの名前を変更し、[ 保存] をクリックします。Adobe Acrobat は、デフォルトでドキュメントを Excel ファイルとしてエクスポートします。
PDFテーブルを最初から作成する時間を節約するには、オンラインPDFコンバーターを試すことを検討する必要があります。これらの強力なツールを使用すると、PDFファイルから表形式のデータをすばやく抽出し、Docx、HTML、CSVなどのさまざまな形式でエクスポートできます。これらのツールを使用すると、使いやすいインターフェイスのおかげで、数回クリックするだけでPDFドキュメントからテーブルを簡単に抽出できます。
使用を検討する必要があるオンラインPDFテーブルエクストラクタをいくつか紹介します。
i2PDF PDFを使用すると、PDFドキュメントのテーブルをDOCX、CSV、XMLなどのさまざまな形式にすばやく抽出できます。このツールは、ドキュメント内のテーブルを長方形でマークすることで効率的に認識する自動検出テーブル機能も備えています。このツールは、テキストから表を抽出するためにのみ使用でき、画像ベースのPDFは使用できないことに注意してください。
このPDFテーブルエクストラクタを使用してPDFドキュメントからテーブルを削除する方法は次のとおりです。
ステップ1.i2PDF メインページに移動し、[ ファイルの選択 ] をクリックして、テーブルから抽出するファイルをアップロードします。または、PDFファイルをユーザーインターフェイスにドロップすると、自動的にアップロードされます。
ステップ2.[ オプション ]をクリックして、テーブルを保存するためのファイル形式を選択します。 [PDFからテーブルを抽出]をタップすると、ファイルが自動的にダウンロードされます。
Convertioには、PDFファイルからテーブルをすばやく簡単に抽出できる使いやすいインターフェイスがあります。ユーザーがファイルをさまざまな形式に変換できる他のツールとは異なり、Converioを使用している場合にのみドキュメントをCSVに変換できます。コンピュータのストレージ、Dropbox、または Googleドライブからファイルをアップロードするだけで、ソフトウェアがプロセス全体を完了するため、変換プロセスは簡単です。
Convertioを使用してPDFからテーブルを抽出するときに従う必要のある手順を確認してください。
ステップ1.Convertioのメインインターフェイスで、をクリックします ファイルを選択 画像付きのPDFドキュメントをアップロードします。 これは、Dropbox またはGoogleドライブを介して行うこともできます。
ステップ2.アップロードしたら、[ 変換]をクリックすると、ドキュメントが自動的にCSVファイルに変換されます。
PDFテーブルを使用すると、PDFファイルをCSVおよびExcel形式にすばやく変換できます。このプラットフォームを使用してファイルを変換することは、直感的で使いやすいインターフェイスを備えているため、数回クリックするだけで実行できます。オンラインベースのツールとして、さまざまなオペレーティングシステム間で完全に機能します。さらに、書式設定がそのまま残っているため、ドキュメントの出力は高品質です。
PDFテーブルを使用してPDFドキュメントからテーブルを抽出する手順は次のとおりです。
ステップ1.[PDF テーブル] メイン ページで、[ PDF の変換] をクリックします。表のあるPDFを見つけて、アプリケーションで開きます。
ステップ2.変換が完了したら、[ Excel としてダウンロード ] をクリックしてドキュメントをダウンロードします。[ Excelとしてダウンロード]の横にある矢印をクリックすると、ドキュメントの形式を変更できることに注意してください。
また、次のものが必要になる場合もあります。
PDFをJPGに変換する方法:初心者向けのステップバイステップチュートリアル
Nanonetsは、PDFファイルからテーブルをすばやく効率的に抽出する方法を探している場合に便利なツールです。ツールにドキュメントをアップロードするだけで、ドキュメントからすべてのテーブルとテキストを抽出できます。また、ファイルのアップロードと変換をすばやく簡単にする使いやすいインターフェイスも備えています。
ナノネットを使用してPDFからテーブルを抽出する手順は次のとおりです。
ステップ1.ツールのメインインターフェイスで、PDFファイルをドラッグアンドドロップしてアップロードするか、[ PDFまたは画像のアップロード ]オプションをクリックします。
ステップ2. テキストと表を抽出するか、表 のみを抽出するかを選択します 。 [ CSV に変換 ] をクリックして、変換プロセスを開始します。ファイルは自動的に変換され、ダウンロードされます。
PDF ドキュメントからのみテキストと表または表を抽出する場合は、このガイドで取り上げている PDF 抽出表ツールの使用を検討する必要があります。好きなオプションに応じて、フォーマットをそのまま維持しながら、PDFドキュメントからテーブルを簡単に抽出できます。
定期的にインターネットに接続している場合は、PDFファイルからテーブルを抽出するのに問題はありません。PDFを定期的に操作する場合は、外出先で作業する柔軟性を提供できるため、オフラインツールが最適です。
関連記事:
[効率的なPDFのヒント]PDFドキュメントのURLリンクを無料で作成する方法
代替プレビュー:コンピューターでPDFをTIFF/GIF / BMPに高速変換
PNGをPDFに変換する方法:完璧な結果を達成するためのガイド





 PC版ダウンロード
PC版ダウンロード  Mac版ダウンロード
Mac版ダウンロード 

