PDFからテキストを抽出する方法をお探しですか?最良の結果を得るための最高のオンラインおよびオフライン抽出器の内訳は次のとおりです。
PDFからテキストを抽出できるPDFリーダーはほとんどないため、PDFテキストの抽出は思ったほど簡単ではありません。この問題は、PDFに簡単にコピーして貼り付けることができないテーブルやその他の形式の非線形データが含まれている場合に悪化します。ただし、多くのソフトウェアツールは、PDFテキストおよび画像ベースのドキュメントからテキストを抽出するのに役立ちます。これらのツールについては、こちらをお読みください。
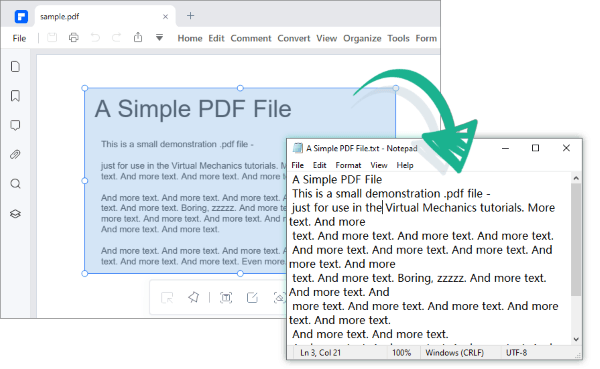
PDFファイルからテキストを抽出したいが、安定したインターネット接続のある場所での作業に限定したくない場合は、オフラインテキスト抽出ツールを検討する価値があります。ほとんどのオフラインツールには光学式文字認識(OCR)機能があり、フォーマットをそのまま維持しながらPDF上の画像からテキストをすばやく抽出できます。
オフラインのテキストからPDFへの抽出機能は、WindowsおよびMacOSと互換性があり、複数のドキュメントを同時にテキスト抽出できます。今日試してみる価値のある最高のオフラインツールのいくつかを次に示します。
PDF Editor を使用すると、ユーザーは画像やフォントサイズを維持しながら、ドキュメントからテキストをすばやく抽出できます。PDFからのこのテキスト抽出ツールは、OCRを使用してドキュメントをスキャンし、画像ベースのPDFドキュメントからテキストを正確に検出します。それでも、ソフトウェア編集機能を使用してテキストベースのPDFドキュメントを抽出するためにソフトウェアを使用することができます。
PDFドキュメントからCSVやExcelなどの他のフォームに整理された形式でテーブルを抽出することもできます。さらに、このPDFエクストラクタを使用すると、PDFドキュメントからバッチデータを抽出でき、MacOSやWindowsなどのさまざまなオペレーティングシステムで使用できます。
このツールを使用する主な機能を確認してください。
PDFをテキストに抽出する準備はできましたか?知っておくべきpdfテキスト抽出手順は次のとおりです。
01月 PDFエディター をコンピューターにダウンロードしてインストールします。[ ファイルを開く]をクリックしてテキストを抽出するPDFファイルを選択します。
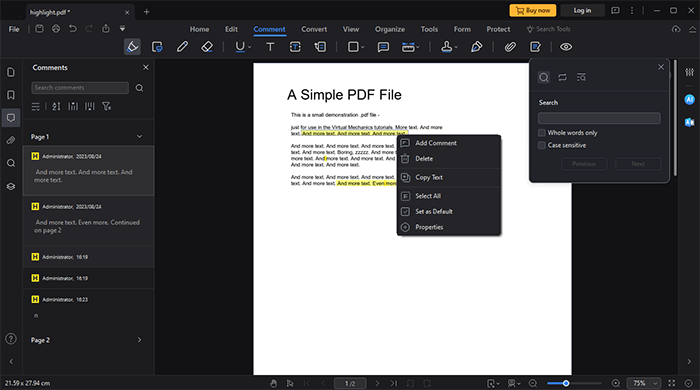
02月[ 編集 ] タブ セクションに移動し、右上の領域にある [ 編集 ] スイッチ ボタンを選択します。抽出するテキストを選択して右クリックし、[コピー]をクリックします。
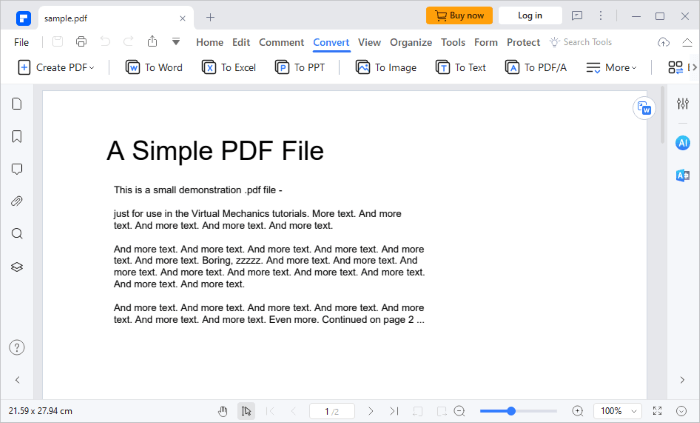
03月他のオプションは、PDFドキュメントをWordに変換することです。これを行うには、[変換]タブの下にある [Wordへ ]を選択します。ポップアップウィンドウが表示されます。[ 保存] をクリックして 、PDF を Word に変換します。文書は自動的に Word に変換され、新しいファイルからコンテンツを抽出できます。
あなたも疑問に思うかもしれません:
iPhoneのバックアップからテキストメッセージを抽出する究極の方法[最新チュートリアル]
これ以上の制限はありません:Macおよびindowsで保護されたPDFからテキストをコピーする方法
PDF Gear Text Extractorは、PDFにテキストを書き込んだり、ドキュメントに署名を追加したりするなど、さまざまな機能を実行できるツールが豊富な主要なPDFエディターの1つです。また、PDFからテキストを抽出したい場合にも便利です。このツールは無料でダウンロードして使用でき、インドウズとMacOSの両方で使用できます。PDFGearを使用して画像ベースのスキャンされたPDFからテキストを抽出する場合は、OCR(光学式文字認識)ツールを使用する必要があります。
PDFGearを使用してPDF画像からテキストを抽出する手順を確認してください。
ステップ1.コンピューターに PDFGear アプリケーションをダウンロードしてインストールし、実行します。メインインターフェイスで、をクリックします ファイルを開く ボタンをクリックすると、コンピューターの ファイルエクスプローラー にリダイレクトされ、編集するPDFを選択します。
ステップ2.ソフトウェアのメインインターフェイスのタブセクションで、[ ホーム]をクリックし、マウスの左ボタンをクリックしたままにして、テキストを抽出する領域を選択します。完了したら、[ 完了] をクリックして、書式設定を失うことなく画像 PDF からテキストを抽出します。
オンラインツールは、PDFドキュメントからテキストを抽出するための迅速かつ簡単な方法を提供します。バッチファイル処理のオプションを提供するオフラインツールとは異なり、ほとんどのオンラインツールでは、複数のPDFドキュメントからテキストを抽出できません。このオプションを使用している場合、特定の時間にテキストを抽出できるファイルサイズまたはページ数に制限があります。
PDFからオンラインですべてのテキストを抽出するのに役立ついくつかのツールを次に示します。
PDFキャンディーは、歪みなくPDFからテキストを抽出するための信頼性の高いツールです。このオンラインツールは、アップロードされたPDFドキュメントにOCRを自動的に適用し、抽出するテキストをキャプチャします。オンラインベースのPDFからテキストへの抽出ツールとして、プログラムやアプリケーションをダウンロードする必要がありません。あなたがしなければならないのはあなたの文書をアップロードして、数回クリックするだけで変換されたファイルを取得することです。
PDFキャンディーを使用してPDFからテキストを抽出する方法を確認してください。
ステップ1.PDFキャンディー抽出テキストページに移動し、[ ファイルの追加 ]オプションをクリックします。ファイルをメインのユーザーインターフェイスにドラッグアンドドロップしたり、 Dropbox またはGoogleドライブ経由でアップロードしたりすることもできます。ファイルは自動的に変換されます。
ステップ2.[ ファイルのダウンロード ] をクリックして、ドキュメントをダウンロードします。Googleドライブまたはドロップボックスにアップロードするオプションもあります。ダウンロード後、[ファイルの削除]をクリックして変換された ファイルを削除します。
PDFクリエーターオンラインは、簡単なクリックでPDFファイルからテキストの迅速な抽出を提供します。このツールを使用すると、最大 サイズ250MBまで複数のドキュメントを同時に処理できます。抽出プロセスには数秒しかかかりません。
ステップ1.[ ファイルの選択] をクリックして PDF ファイルをアップロードします。URLを介してファイルをアップロードしたり、ユーザーインターフェイスにドラッグアンドドロップしたりすることもできます。テキストは自動的に抽出されます。
ステップ2.[ ダウンロード ]をクリックして、抽出したテキストをコンピューターに保存します。
画像からテキストへの変換は、画像PDFファイルからテキストを抽出する際の頼りになるツールである必要があります。このツールは、PDFからテキストを効率的に抽出する光学式文字認識サービスを備えています。ファイルを変換した後、テキスト(txt)またはWord(doc / docx)形式でドキュメントをダウンロードできます。ファイルのダウンロードに加えて、クリップボードにコピーを使用してPDFからテキストをリアルタイムでコピーできます。このツールは、ファイルを抽出する前に個人情報を提供する必要がないため、使いやすいです。
画像からテキストへの変換を使用してPDFからテキストをすばやく抽出する手順は次のとおりです。
ステップ1.PDFドキュメントをユーザーインターフェイスにドラッグアンドドロップします。ドキュメントをコピーしてインターフェイスに貼り付けることもできます。[ 送信] をクリックして、ドキュメント変換プロセスを開始します。
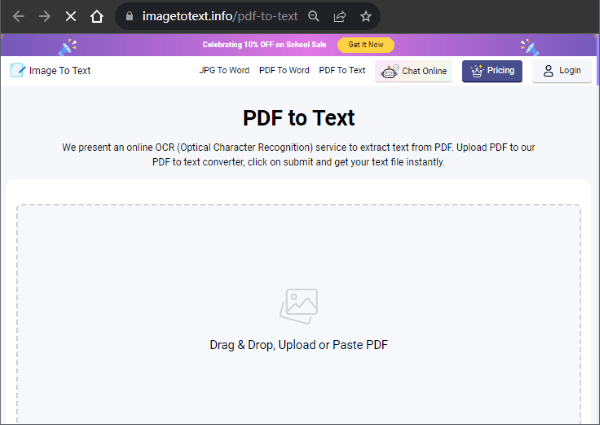
ステップ2.[ドキュメント として保存 ]をクリックしてドキュメントをダウンロードするか、[ クリップボードにコピー ]をクリックしてオンラインで編集します。
続きを読む:
視覚的な宝物のロックを解除する:MacでPDFから見事な写真を抽出する方法
代替プレビュー: Mac で PDF を TIFF/GIF /BMP に高速変換
OCR 2 Editは、画像ベースのPDFテキストをすばやく抽出する場合は、好みのオンラインPDFテキスト抽出ツールである必要があります。抽出されたテキストは、さまざまな種類のドキュメントエディタを使用して開くことができます。このプラットフォームには、ファイルのアップロードと抽出を高速化する使いやすいインターフェイスもあります。
PDFからテキストを抽出する際に実行する必要のある手順は次のとおりです。
ステップ1.[ ファイルの選択 ] をクリックして、テキストを抽出する PDF を選択します。ユーザーインターフェイスにドラッグアンドドロップして、ドキュメントをアップロードすることもできます。
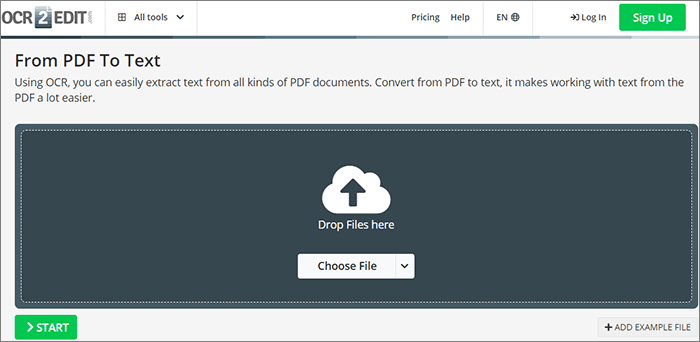
ステップ2.ドキュメントの言語を選択し、フィルタを適用するかどうかを選択して、[ 開始] をクリックします。ドキュメントは自動的にテキストに変換されます。ドキュメントをZipファイルとしてダウンロードするか、クラウドにアップロードします。
Sejda PDFを使用すると、簡単な手順でPDFからテキストをすばやく抽出できます。このツールは、変換されたすべてのファイルが2時間後に自動的に削除されるため、アップロードされたファイルの安全性を保証します。また、50 MB未満で200ページ以下のドキュメントを好きなだけ抽出することもできます。
sejda PDFを使用してPDFからのみテキストを抽出する手順は次のとおりです。
ステップ1.テキストを抽出したいファイルをアップロードします。または、Dropbox、 Google Drive、OneDrive、Web アドレスからファイルをアップロードすることもできます。
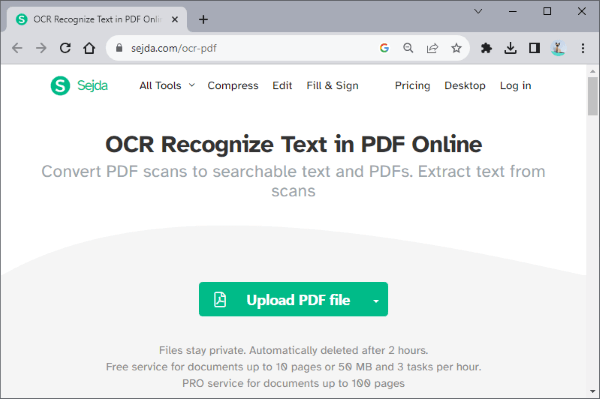
ステップ2.[ テキストの 抽出]をクリックして、抽出プロセスを開始します。
ステップ3.[ ダウンロード ]をクリックすると、ドキュメントがコンピューターに自動的に保存されます。Dropbox、OneDrive、Googleドライブに保存するオプションもあります。ファイルをダウンロードしたら、[ ファイルの削除 ]をクリックしてドキュメントを自動的に削除できます。
スキャンしたPED画像またはテキストベースのPDFドキュメントの編集は、編集可能な形式でテキストを抽出しない限り簡単ではありません。ただし、このガイドに記載されているツールのいずれかを使用すると、このようなタスクを簡単に実行できます。多くのドキュメントで作業している場合は、オフラインツールが非常に役立つ場合があります。テキストをすばやく抽出したいドキュメントがいくつかある場合は、オンラインツールを試す価値があります。選択したテキスト抽出器に関係なく、ドキュメントの元の書式を確実に保持できます。
関連記事:
[オフィスのヒント] あなたが試すべきPDFから画像を抽出する7つの方法





 PC版ダウンロード
PC版ダウンロード  Mac版ダウンロード
Mac版ダウンロード 

