PDFは、その普遍的な互換性とドキュメントの整合性を維持する能力により、デジタルドキュメントの広範な領域で普及しています。それでも、スキャンしたPDFまたは画像ベースのPDFからテキストを抽出するのは多忙な場合があります。幸い、適切なソフトウェアと手順を使用すると、品質を損なうことなくPDF画像をテキストにすばやく変換できます。
プログラムには光学式文字認識(OCR)テクノロジーが搭載されており、写真に隠されたテキストにアクセスできます。これにより、他のコンテキストで PDF 画像を編集、検索、および再利用できます。この記事では、PDF画像からテキストを抽出する方法について、他の便利なポインタとともに詳しく説明します。研究者、専門家、学生のいずれであっても、PDF画像からテキストを抽出する方法を学びます。
アクセシビリティと使いやすさにより、多くのオフラインソフトウェアアプリはPDF画像をテキストに変換することに優れています。作業の機密性を保護する必要がある場合、変換プロセスを完全に制御する必要がある場合、またはインターネットにアクセスできない状況では、オフラインツールが便利です。画像PDFからテキストを抽出するための優れたオフライン方法は次のとおりです。
PDFelement は、スキャンしたドキュメントをインポートし、WordまたはTXTファイルとしてエクスポートすることでPDF画像内のテキストを変更できる堅牢なPDFエディターです。これにより、標準のテキストドキュメントと同じ方法で編集が容易になります。
PDF要素は、PDFを画像との間で変換することに加えて、DOCX、PPTX、XLS、HTML、RTF、TXT などのさまざまなファイルタイプとの間でPDFを変換することもサポートしています。使いやすさは、その特徴の1つです。PDFelement はクロスプラットフォームで、Mac OS X、AAAWindowsAAAA、iOS、Android をサポートしています。
最高のPDFエディターの1つになるためのPDF要素のいくつかの重要な機能は次のとおりです。
では、PDF要素を使用して画像PDFをテキストにどのように変換しますか?
01月PDF要素をダウンロードして実行します。画像ファイルをプログラムにドロップして開きます。
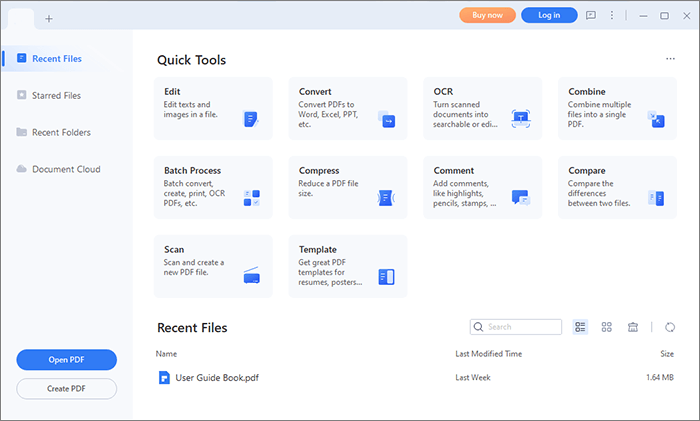
02月OCRを有効にするには、「ツール」をクリックし、「OCR」ボタンをタップします。「編集可能なテキストにスキャン」オプションを選択します。ページと必要な言語を選択し、[適用]をクリックして、写真のテキストとタイトルを選択した言語に翻訳します。
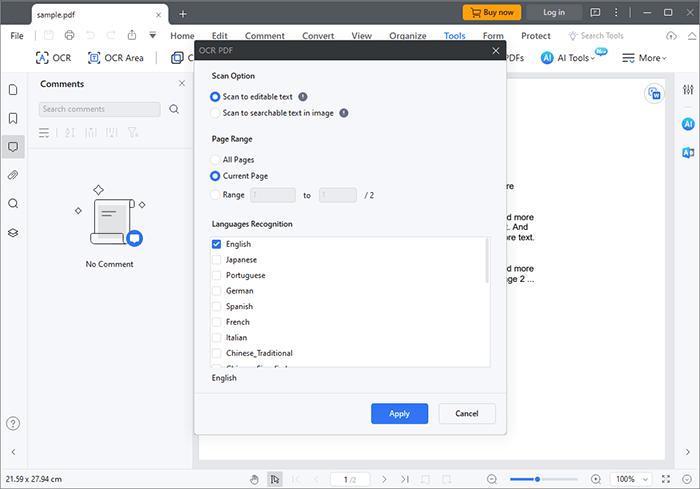
03月結果のホームページで「変換」>「テキストに変換」をクリックします。ドロップダウンオプションから「TXT」を選択し、選択したフォルダにファイルに名前を付けて保存し、[OK]をクリックします。
続きを読む:
画像をテキストに変換するためのトップ5の無料OCRソフトウェア
テキストからPDFへの変換が簡単に:ステップバイステップの変換ハンドブック
Adobe Acrobat for Windows および Mac を使用すると、編集および検索可能なテキストドキュメントを取得するために、PDF を再入力、再フォーマット、または再スキャンする必要がなくなります。元のフォントと構造を維持しながら、組み込まれている堅牢なOCR機能を使用して、スキャンしたPDFをテキストファイルに変換できます。
次の簡単な手順に従って、Adobe Acrobat を使用して PDF 画像からテキストを抽出します。
ステップ1.ダウンロード後にAdobe Acrobatを起動し、OCRするスキャンしたドキュメントを開いて[ツール]を選択します。「テキストを認識する」を選択することから始め、続いて「このファイル内」を選択します。
ステップ2.コントロールを使用してOCRを調整できます。テキスト認識を続行するには、翻訳したい文書がシステムのデフォルトとして設定された言語で書かれている場合は「OK」を選択します。「編集」をクリックし、「プライマリOCR言語」>「PDF出力スタイル」>「ダウンサンプル先」を選択します。
ステップ3.PDF画像を右クリックし、「フォーマット付きでコピー」を選択します。PDF を OCR すると、認識されたテキストが元のファイルに保存されます。ただし、画像をOCRすると、画像はテキストと一緒に新しいPDFファイルに保存されます。
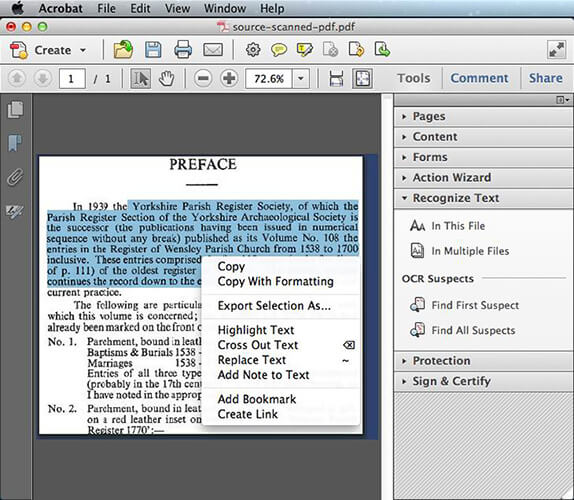
ステップ4.[選択範囲を名前を付けてエクスポート]タブに移動します。OCRされたファイルをエクスポートするには、[名前を付けて保存]を選択し、ファイルタイプとして[Word文書]を選択します。新しいファイルの場所を選択して保存します。
ソーダPDFは、PCおよびモバイル用の50を超えるPDFアプリケーションのスイートであり、PDFファイルの変換、保護、作成、 および編集を簡単にします。組み込みのOCRテクノロジーにより、画像付きのPDFを編集可能なテキストにスムーズに変換できます。
ソーダPDFを使用してPDF画像からテキストをコピーする方法を学びます。
ステップ1.ソーダPDFをダウンロードして実行します。Create & Convert モジュールで "Advanced" を選択し、"PDF to TXT" を選択します。
ステップ2.変換が必要なページを特定します。追加の設定にアクセスするには、3つのドットを選択します。
ステップ3.フォルダアイコンをクリックして、デフォルトの保存場所を変更します。OCRを使用して、スキャンしたファイルを編集可能にします。次に、「変換後にTXTドキュメントを開く」をマークし、「エクスポート」をクリックします。
ステップ4.ファイルの変換が完了するとすぐに、このアラートが表示されます。
好きかもしれません:
アートをマスターする:プロのようにPDFをWordにコピーする方法[5つの方法]
PDFからWordへのOCRソフトウェアレビュー:精度と効率を解き放つ
オンラインPDF画像テキストコピーは、簡単で効率的なソリューションです。iLovePDF、PDF2Go、オンラインOCRなどのオンラインアプリケーションのおかげで、追加のソフトウェアをインストールせずにPDF写真をテキストに変換できます。PDF画像をオンラインでテキストに変換するためのいくつかの便利な方法を次に示します。
PDF2Goの多くの印象的な機能の1つは、画像のPDFをテキストにすばやく簡単に変換できるOCRです。PDF2GoのOCR機能を使用すると、重要な詳細を簡単に抽出し、編集可能な形式でドキュメントを開くことができます。
PDF2Goを使用してPDF画像をテキストに変換する3つの簡単な手順を次に示します。
ステップ1.PDF2Go Webサイトで、ここにファイルをドロップするか、[ファイルを選択]をクリックします。
ステップ2.OCRで変換し、「スタート」ボタンをタップします。
ステップ3.変換後のファイルをダウンロードする。
オンラインOCRを使用すると、スキャンしたPDFを編集可能なテキストに簡単に変換できます。さらに、任意の画像ファイルタイプ(JPG、BMP、またはPNG)は、元のファイルのフォーマットを維持しながらテキスト出力形式に変換できます。Online OCR は、Windows、MacOS、および Linux と互換性があります。
オンラインOCRを使用してPDF画像をテキストに変換するには、以下の簡単な手順に従ってください。
ステップ1.オンラインOCRページで、[ファイルの選択]をクリックし、[英語]言語と出力形式を[テキストプレーン]として選択します。次に、「変換」ボタンを押します。
ステップ2.出力ファイルをダウンロードします。
関連項目:
[包括的なチュートリアル]PDF を Word 文書として保存する方法
[簡単なPDFソリューション]スキャンしたPDFを複数の方法でWordに変換する方法
OCR2EDITは、ユーザーがスキャンしたPDFからテキストを読むことができる最先端のプログラムです。ユーザーフレンドリーなインターフェースにより、スキャンした写真からテキストをすばやく正確にプルできます。
OCR2EDITを使用してスキャンしたPDF画像をテキストに変換する方法については、以下の簡単な手順に従ってください。
ステップ1.OCR2EDIT Webページを開き、[ファイルの選択]をタップするか、ここにファイルをドロップします。
ステップ2.OCR設定では、必要に応じて構成します。次に、「開始」をクリックします。
ステップ3.変換後のファイルをダウンロードする。
iLovePDF、PDF関連のタスクのための有名なオンラインプラットフォーム。画像から作成されたPDFを編集可能なテキストファイルに変換する簡単な方法を提供します。iLovePDF OCRソフトウェアを使用すると、スキャンした画像やグラフィックコンテンツから作成されたPDFのテキストにアクセスして操作できます。これらの3つの重要な手順に従って、iLovePDFを使用してスキャンしたPDF画像をテキストに変換する方法を学びます。
ステップ1.iLovePDFのウェブサイトで、「PDFファイルを選択」をタップするか、ここにPDFをドロップします。
ステップ2.「OCR PDF」をタップします。
ステップ3.PDFをダウンロードして、好きなように選択して検索できます。
見逃せない:
TIFFをPDFに変換する方法:オンラインおよびオフラインの方法が明らかに
プロのように写真をPDFにスキャンする方法は?あなたの究極のガイド
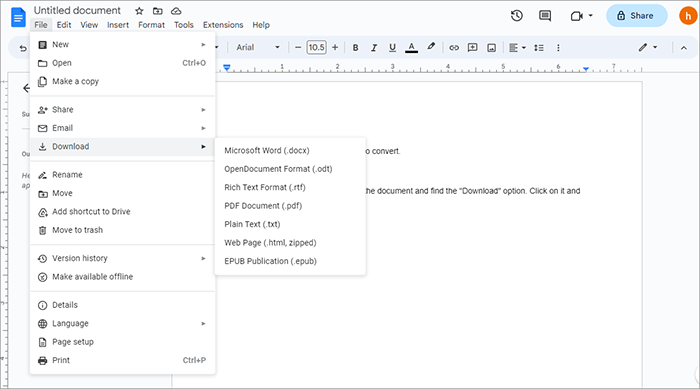
Googleドキュメントは、ユーザーがPDF、Word、画像、およびその他の形式を開いたり、読んだり、編集したり、 エクスポートしたりできる無料のオンラインサービスです。スキャンしたPDFや画像に対してもOCRを実行できます。ただし、GoogleドキュメントのOCRを使用する場合は、フォーマットを手動で修正します。以下の簡単な手順に従って、PDFから画像とテキストを抽出します。
ステップ1.[マイドライブ] タブで Google ドライブ にファイルをアップロードします。
ステップ2.PDF 画像を右クリックします。「プログラムから開く」>「Googleドキュメント」を選択します。
ステップ3.これで、ファイルのコンテンツが Google ドキュメントで編集可能になりました。「ファイル」>「ダウンロード」>「プレーンテキスト(.txt)」をクリックします。
PDF画像をテキストに変換する方法を知っていると、ドキュメントをよりアクセスしやすく使いやすくするのに役立ちます。この目的のために利用可能なさまざまな選択肢の中で PDF要素 を利用することをお勧めします。その革新的でわかりやすいOCR機能により、群衆から際立っています。画像からの正確なPDFテキスト変換のために今すぐダウンロードしてください。
関連記事:
PDFをWordに簡単に埋め込むにはどうすればよいですか?[ヒントとコツ]
【4つの省力化のコツ】PDF ドキュメントにテキストを追加する方法
PDFをGoogleドキュメントに挿入する方法:すばやく簡単な手順
テキストがなくなる:PDFからテキストを削除する方法[完全なチュートリアル]





 PC版ダウンロード
PC版ダウンロード  Mac版ダウンロード
Mac版ダウンロード 

